
以前、本ブログで国語教科書全文をテキストデータ化する方法について書いたが、別の方法を発見したので紹介しよう。
(以前紹介した方法はこちら↓)
★2018年9月24日エントリー記事
『国語教科書全文(本文)を簡単にテキストデータ化する方法 ~「読むこと」の授業準備を効率よく行うために~』
先日紹介した方法と異なるのは、ドキュメントスキャナーを使う点だ。
私は富士通のScansnap(S1500)という機種を使っているが(もう7年前の機種!)、このScansnapの読み取り設定を少し変えるだけで、簡単にテキストデータ化が可能だ。
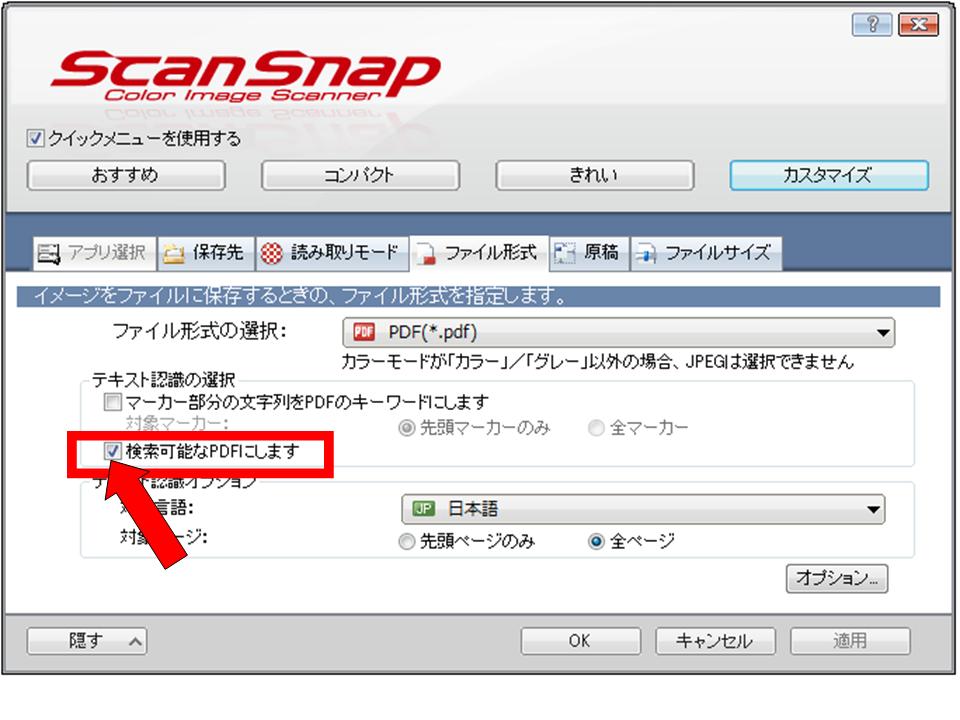
上の図のように、ファイル形式でテキスト認識の選択を「検索可能なPDFにします」にする。そうすると読み取った画像の中のテキスト部分を抽出できるようになる。

このように本文をコピー&ペーストしてWordなどで編集すればよい。

この方法のほうが、前回紹介した方法よりも簡単(笑)
何で早く気付かなかったのだろう。
投稿者プロフィール
-
誰もが自分の個性や才能を生かして、望む人生を自由に生きられる社会の実現を目指しています。今まで教育に携わりながらコーチング、心理学、カウンセリング、占星学、学習法など、個人の成長や能力開発に関わることを学んできました。このブログで発信する情報が、自己理解や他者理解を深めるきっかけの1つになれば幸いです。
詳しいプロフィールはこちら。
最新の投稿
- 2026年7月20日未分類AIで個人面談資料の整理
- 2026年6月14日未分類ベロシティレッドのRX8
- 2026年5月18日未分類授業づくりハックの書籍原稿執筆
- 2026年4月26日未分類2026年春の桜